为什么写这篇文章?
最近在整合storm+kafka一直纠结于重复数据的读取,重新启动topology更是把kafka的数据扫描一遍,
【如果线上逻辑较重,并且还要往数据库里面插入数据是不是有很多重复数据了!】
为什么写这篇文章?
最近在整合storm+kafka一直纠结于重复数据的读取,重新启动topology更是把kafka的数据扫描一遍,
【如果线上逻辑较重,并且还要往数据库里面插入数据是不是有很多重复数据了!】
软件环境
zookeeper-3.4.6.tar.gz
kafka_2.9.2-0.8.1.1
apache-storm-1.0.1.tar.gz
实践出真知
那我们知道这kafka和storm都是依赖zk的,并且我们在创建topology的时候也是把offset写入到zk
但是一开始的程序是非常奇怪的,zk并没有创建我所指定的目录和id。
先来看一个”错误”的例子
|
|
|
|
上面这个例子是无法在zk中创建/topic2/split的,至于为什么我在后面会说明。
由于也是最近几天才开始撸起来的所以我就各种搜索,在一个blog中找到了说明
原文
此处需要特别注意的是,要使用backtype.storm.topology.base.BaseBasicBolt对象作为父类,否则不会在zk记录偏移量offset数据。
后来我修改bolt继承该类确实在zk中创建出了topic,但是至于为什么并没有详细说明。
我们先来看看修改后的code。
|
|
|
|
|
|
原谅我写了两个例子吧!
好的,上面一大段代码是修改过的。此时进入zkcli已经创建出来了我们所需的路径
并且已经记录了offset

读取数据的时候就从这里开始了。
那好,为啥继承了BaseBasicBolt类就可以,而BaseRichBolt类就不行呢。
走进源码
首先看看KafkaSpout类的open方法做了一些初始化的工作
下图才是我么要看的

不用在意其它方法,直接进入commit()方法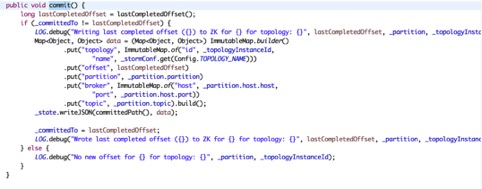
看到没, 只要if成立就会在zk中创建数据。但是为什么不能进入呢,来看看lastCompletedOffset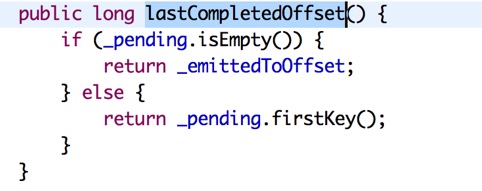
当你debug到这里的时候首先获取的是第一个key,这个map的key是offset,value是timestamp
读一次会和上一次进行比较,最终在里面重新赋值最新的offset。
仔细观察,如果继承BaseRichSpout类,调用过后map的key依旧存在,而BaseBasicBolt会进行删除,如果不删除的话会在commit判断时候一直相等。
那么,是在什么时候进行删除的呢?如果是你,你会想在什么时候把这份数据进行删除?
对的,当我们确认完毕这条数据被消费后,我们可以进行删除了。
在进行ack之后,我们看到删除map的数据,这样就顺利的在zk里面创建并写入数据。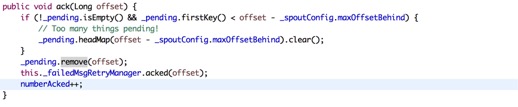
那么,如果我就想继承自BaseRichBolt类,那有办法实现吗?肯定的,你只需要自己ack一下就行了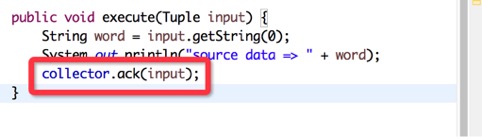
ok,此时你在次打开zkcli查看就存在指定的目录和id,并且重启topology也不会重新读取历史。
总结
BaseBasicBolt没有提供ack而是隐示进行了调用,而BaseRichSpout需要显示调用。

